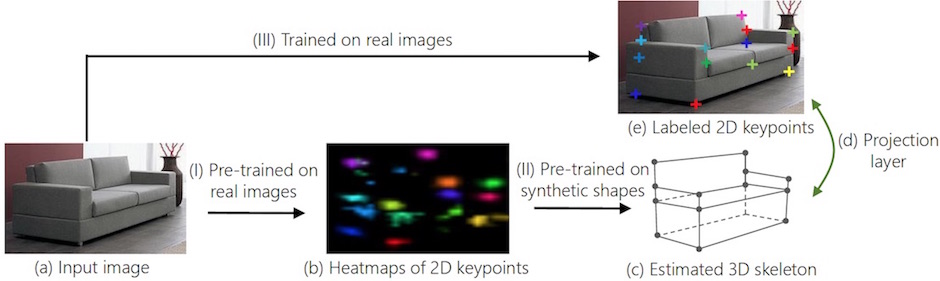
Figure 1: Overview of 3D INterpreter Networks (3D-INN)
Abstract
Understanding 3D object structure from a single image is an important but difficult task in computer vision, mostly due to the lack of 3D object annotations in real images. Previous work tackles this problem by either solving an optimization task given 2D keypoint positions, or training on synthetic data with ground truth 3D information.
In this work, we propose 3D INterpreter Networks (3D-INN), an end-to-end framework that sequentially estimates 2D keypoint heatmaps and 3D object structure, trained on both real 2D-annotated images and synthetic 3D data. This is made possible mainly by two technical innovations. First, we propose a Projection Layer, which projects estimated 3D structure to 2D space, so that 3D-INN can be trained to predict 3D structural parameters supervised by 2D annotations on real images. Second, heatmaps of keypoints serve as an intermediate representation connecting real and synthetic data, enabling 3D-INN to benefit from the variation and abundance of synthetic 3D objects, without suffering from the difference between the statistics of real and synthesized images due to imperfect rendering. The network achieves state-of-the-art performance on both 2D keypoint estimation and 3D structure recovery. We also show that the recovered 3D information can be used in other vision applications, such as 3D rendering and image retrieval.
